Assessing demographic bias in named entity recognition
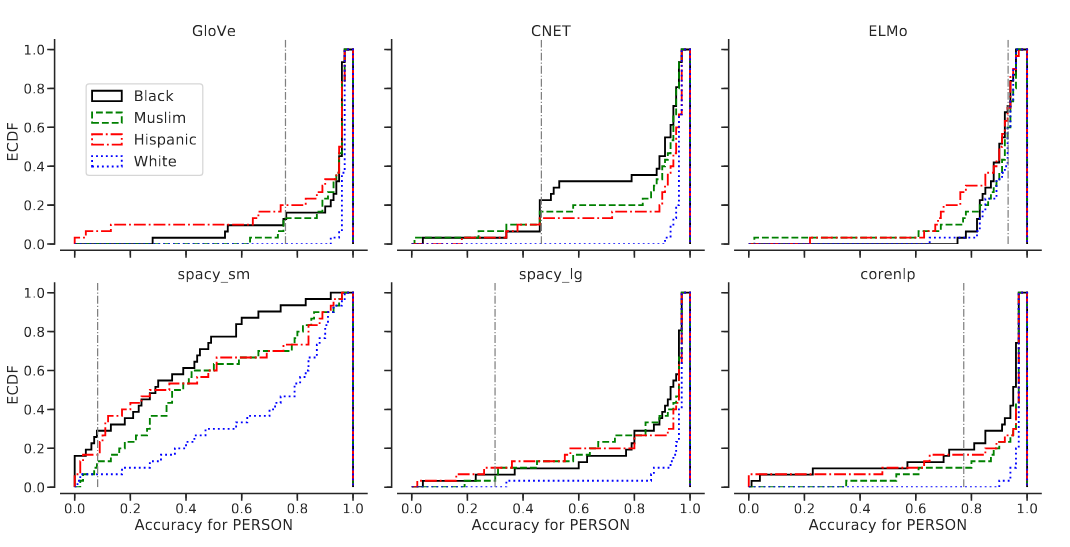
Named Entity Recognition (NER) is often the first step towards automated Knowledge Base (KB) generation from raw text. In this work, we assess the bias in various Named Entity Recognition (NER) systems for English across different demographic groups with synthetically generated corpora. Our analysis reveals that models perform better at identifying names from specific demographic groups across two datasets. We also identify that debiased embeddings do not help in resolving this issue. Finally, we observe that character-based contextualized word representation models such as ELMo results in the least bias across demographics. Our work can shed light on potential biases in automated KB generation due to systematic exclusion of named entities belonging to certain demographics.
Read the full research report
Publication details
Authors: Shubhanshu Mishra, Sijun He, Luca Belli
Publication date: 2020/8/8
Journal: arXiv preprint arXiv:2008.03415
Subscribe to my newsletter to get the latest updates and news